Ich fand für Peewee ein Tutorial zum Bau eines Blogs in Flask. Das war doch hilfreich, wobei ich wenig vom Code verstehe. Keine Überraschung.
Ich kann meine App definieren, dass sie die Einträge aus Coldsweat in Flask ausliest. Eine Editierfunktion wäre schon gut. Ich werde wohl mit zwei Datenbanken agieren.
Am Anfang tippte ich noch, mit zunehmender Konfusion gab ich das auf und klonte die Repo. Alles funktionierte – alles gut.
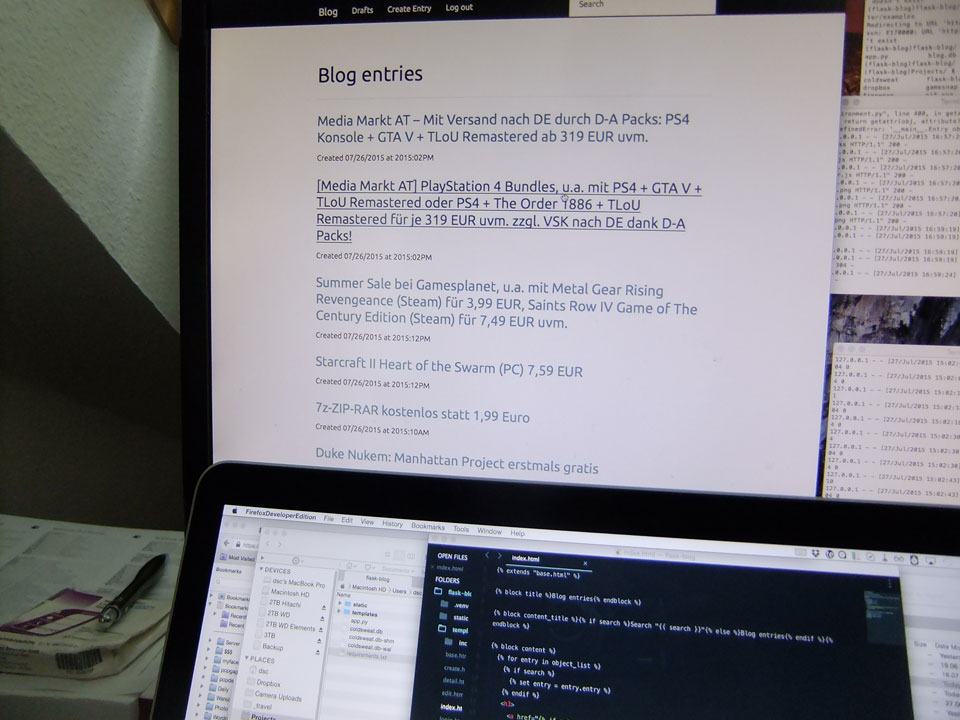
15:35 – Ich machte mich nun daran, die Datenbank von CS als Blog Einträge anzuzeigen. Kopierte die coldsweat.db um, SQLite ist das ja nur. Baute das DB-Ding up: Content und Title blieben, Slug => GUID, timestamp => last_updated_on . Statt published nahm ich is_enabled. Das ganze Refactoring war doch ziemlich wackelig. Ich fügte eine Spalte in der CSDB hinzu „is_enabled“) und änderte ein Jinja Template wegen der timestamp statt last_updated_on
17:00 dann der erste Erfolg. Das Blog Tutorial zeigte die Einträge aus meiner CS Datenbank an. Jetzt müsste ich noch die Slugs generieren und erweitere somit Coldsweat. Zuerst um die extra Zeile, dann um die Slugs. Post-IDs sind wohl besser und schneller.
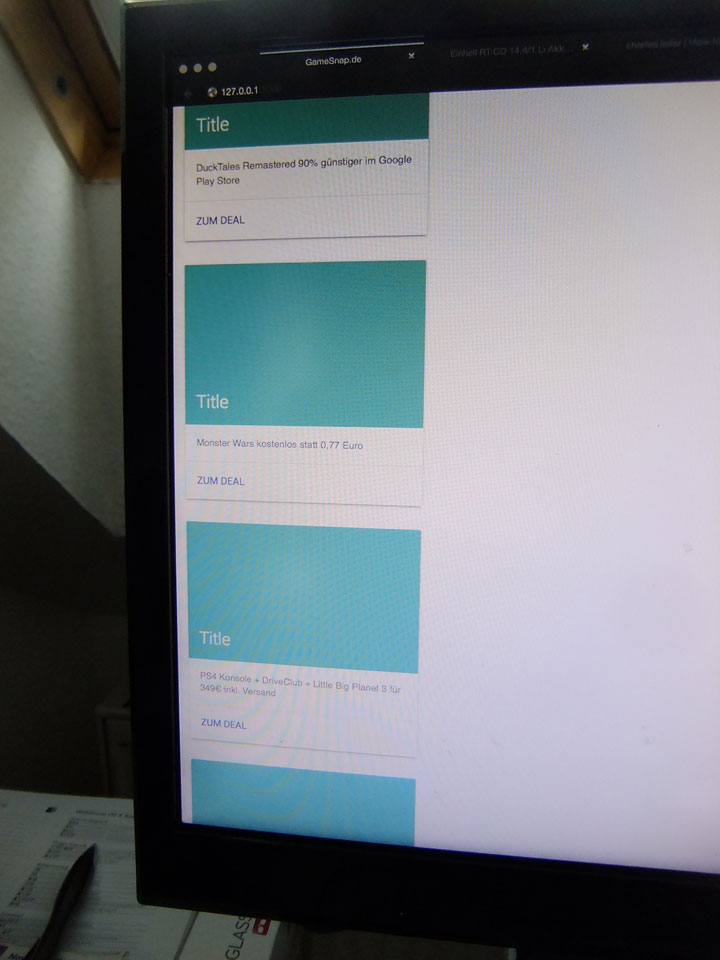
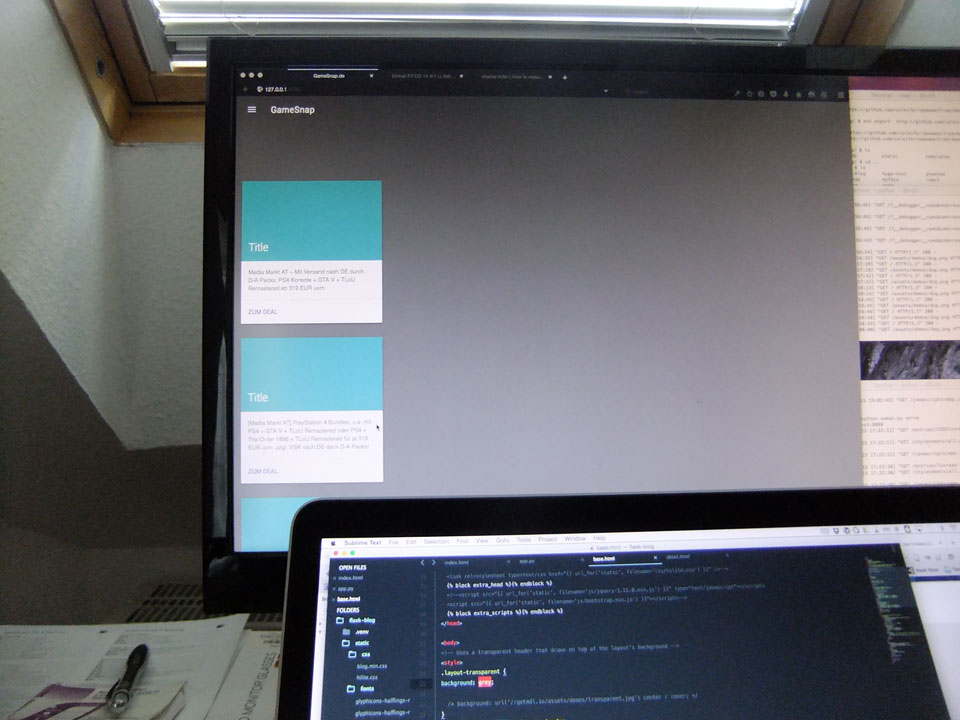
Bis 20:00 kämpfte ich etwas mit dem MDL und Grid Definitionen. Ich denke, dass ich das Android Site-Template, dass Google zur Verfügung stellt, am Ende besser einbinde. Jetzt geht’s doch erst mal um die Funktionalität. Ich muss die Bilder cachen und möglichst skalieren weil Hotlinking hier Fehl am Platz wäre. Danach brauche ich die echte URL, statt die des Blogseintrags. Es ist aber schon mal cool, wie weit ich heute gekommen bin. Mit einer Flask App ziehe ich Daten aus der Coldsweat DB. Der Anfang für einen anderen RSS Viewer mit den Extra Funktionen.
Plan für morgen:
Wordpress RSS lokal ziehen, also noch eine Installaion von Coldsweat – ist schneller zu Testzwecken. Dann die gefundenen Bilder pro Post auf Festplatte speichern – Original und verkleinert. Danach vielleichht noch Einbau in die Datenbank – PostID+Hash.jpg samt Verlinkung im Template. Die schwierigste Sache kommt noch, folgen der ganzen Links auf die Endseite der Anbieter mit Austausch der Affiliate Codes. Aber vielleicht lasse ich das erst mal. Vielleicht sollte ich mir Flask Admin mal genauer anschauen.
Verrückt wurde es am Ende. Die ganzen Links in den Blogs sind gut mit Redirects geschützt und selbst mit PhantomJS kommt man da wohl nicht ohne weiteres ran. Die Lösung mit den ganzen redirects geht über einen headless Browser und am stabilsten wohl mit Watir und Ruby(!). Ich installierte den Watir WebDriver für Selenium und Headless. Auf dem Mac öffnete sich dann Firefox (eventuell hide per open –hide /Applications/Firefox.app/Contents/MacOS/firefox) und besuchte automatsich die Links. Am Ende will ich das ja sowieso auf dem Server laufen lassen.
Es ist schon irre, was alles geht und was man alles bringen müsste. Ruby sieht noch netter aus als Python aber das ziehe ich mir erst mal nicht noch rein. Inzwischen habe ich nach den erfolglosen PhantomJS Versuchen nun aber gute Hoffnung. Die Link-Endpunkte kann ich erst mal erreichen. Auf dem Server sollte das mit Xvfb installieren und Iceweasel auf Debian.
SQLite3 Ruby gibt’s. Demnach wäre das einfach ein Schritt im cronjob, ohne dass ich eine wackelige Verbindung zwischen Ruby in Python aufbauen müsste.
Nun doch 22:30 erst Schluss mit dem Scripten. Eine Proxy dazwischen und man kann quasi unerkannt fast alles scrapen. Immer interessant, was es alles so gibt. Guter Fortschritt heute. Morgen sollte ich auch checken ob der ImageScraper notwendig ist oder cih die Image Links direkt per BS4 aus dem Artikel ziehe. Über Ruby konnte ich schon mal die SQLite DB ansprechen und einen erstes SELECT * ausgeben. Coole Sache, dann die Links auf den Browser lenken und die Resultate zurückschreiben. Mal schnell die Ruby Loop Syntax checken…morgen.



0 Responses to “Flask, Blog, Watir”