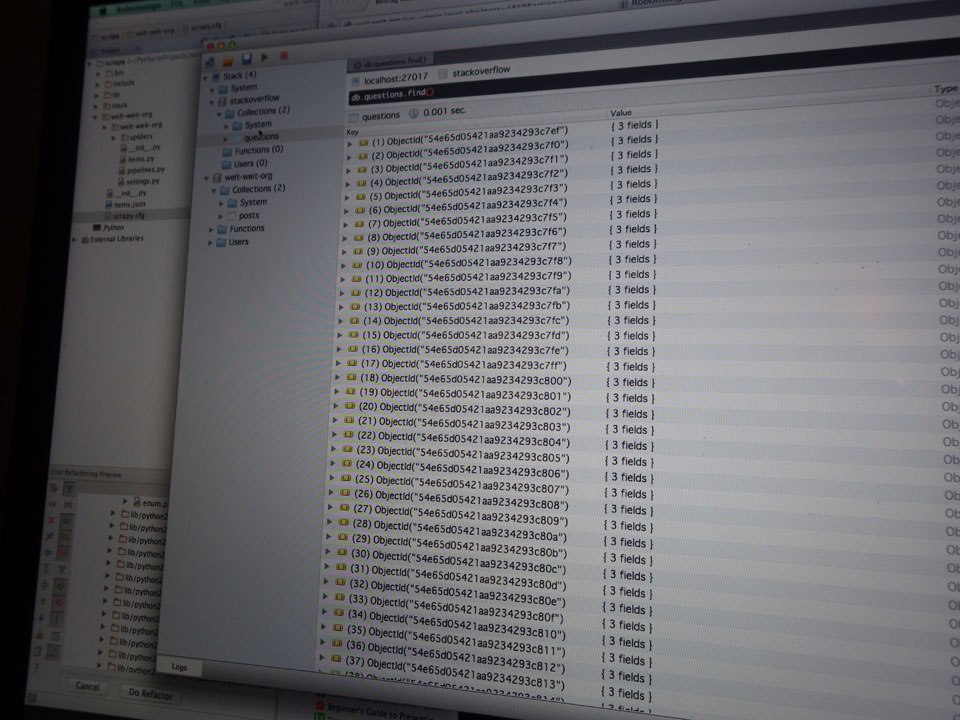
Ich machte einfach mal los und startete ein Tutorial 1 / 2 mit Scrapy + MongoDB. Irgendwie schon das, was ich brauche – XPath finden, die Pipeline bauen und am Ende die Daten sortieren und in die DB.
Von Null aus kapiere ich natürlich wenig,was im Hintergrund läuft (yield) aber das muss ich auch nicht.
Meine Anwendung wird klein und eben auch sehr speziell. Ich war ziemlich froh, dass am Ende alles klappte, auch wenn’s doch nicht so einfach war. Ein paar Typos oder ein Problem mit der Firewall und schon geht das Ding nicht. Jetzt heißt es, die Spider für weitere Seiten zu schreiben – Deduplication der Links und am Ende eben alles in eine Site.
Ich sollte wohl eher meinen Blog als Scraping-Test nehmen. Wenn’s dann später noch mit Proxies los geht, wird’s noch weitaus komplizierter. Alles in allem aber gibt’s so viel auf GitHub, dass es eine Freude ist. Scrapely und Portia sehen auch gut aus aber alles Schritt für Schritt.


0 Responses to “Scrapy + MongoDB”