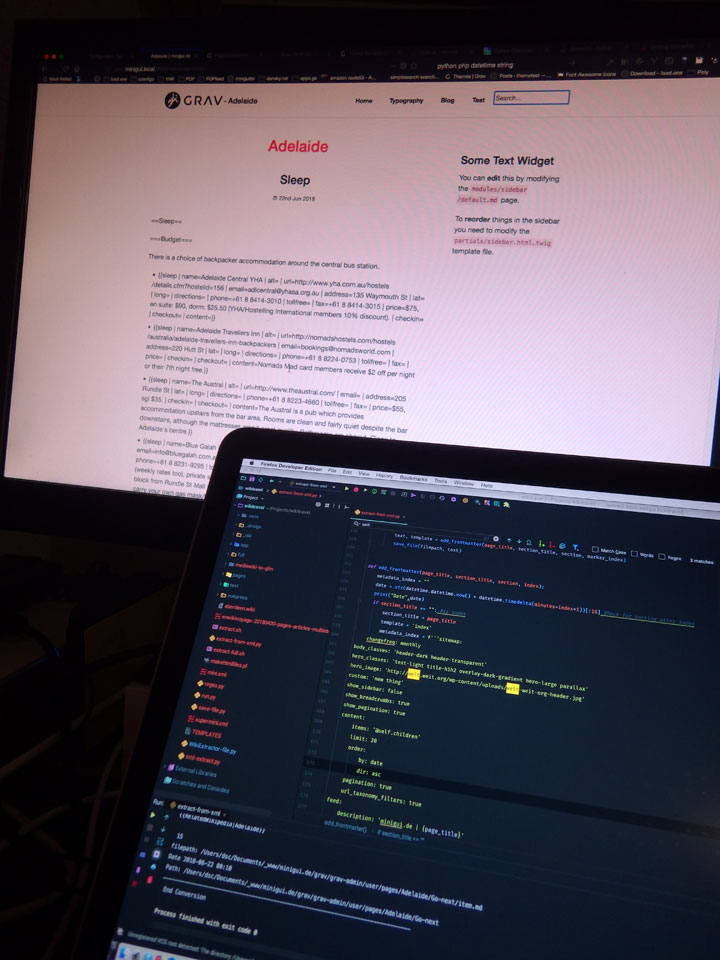
Die Anpassung der kopierten blog-Partials macht die Index-Seiten jetzt schon nutzbar. Ich habe damit alle Sektionen auf einer Seite und kann schon durchklicken.
Über einen kleinen Hack mache ich die Sortierung über datetime, wobei für jeden Index eben eine Minute addiert wird. Das ist keine schöne Lösung, jedoch die schnellste.
Die forward / backward button noch falsch herum, weil Blog eben normalerweise rückwärts läuft.
Ansonsten erledigte ich noch diverse Regex Fixes wie:
text = re.sub("()", "", text, flags=re.DOTALL) (statt dem fehlerhaften „flags=re.MULTILINE“ und nahm unicode-slugify von Mozilla für die Säuberung der Ordner-Namen. Wie ich eventuelle Bilderlinks mit rein bekomme, weiß ich noch nicht. Die ganzen Lizenzen und Autoren müssten ja auch angezeigt werden. Scrapen will ich nicht, weil’s lame wäre.
Den TNTindexer@401 könnte man auch $text limitieren – regex auf nur header und damit die Orte setzen. Das muss ich später machen, denn bei voraussichtlich über 100.000 Seiten, würden sonst zu viele Quatsch-Resultate kommen. Es wäre auch interessant, wie ich die GPS Koordinaten da mit nutze, weil TNTSearch eine GPS-Suche schon mit eingebaut zu haben scheint.
Ansonsten ging ein Discourse update, einkaufen für ca. €20 bei Netto.
Als erste Wikicodes säuberte ich die Headings simple und nicht sonderlich schön:
# Converts the headings by counting the "=" from MWMarkup into Markdown "#"
def convert_headings(wikicode, text):
headings = list(wikicode.ifilter_headings())
for heading in headings:
hlevel = int(str(heading).count('=')/2)
heading_md = str(heading.replace('=', ''))
heading_md = ("\n" + "#" * hlevel + " " + heading_md)
text = text.replace(str(heading), heading_md)
return text
Damit sehen die Seiten schon mal annehmbar aus. Jetzt gibt’s aber noch extrem viele Templates und Sachen zu bearbeiten, bis ordentliches Markdown und damit HTML herauskommt. Schon jetzt, nach ein paar Tagen Arbeit an dem Problem, kommt wieder die Sinnfrage. Werde das Ding aber auch mit Sinnlosigkeit zu Ende bringen. Soweit muss ich mal kommen.





0 Responses to “Grav Page Collections”